
5.1 Primed Generation
Note: All audio samples, both ground truth and generated are resynthesized by passing the pitch contours through our Spectrogram Generator + vocoder. Additionally, all samples are generated by GaMaDHaNi (autoregressive variant).
1. Sample with fast movement in a high voice
Our proposed method is able to continue a similar idea.
Input Prime
Input Prime + Ground Truth Continuation (solid blue + dotted blue contour)
Input Prime + Generated Continuation (solid blue + orange contour)
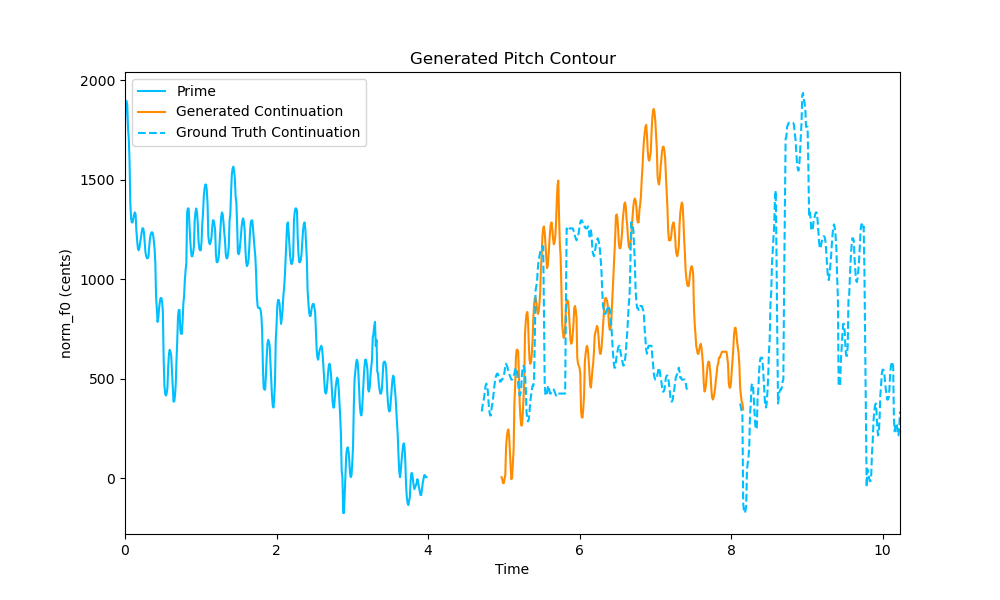
Pitch contour containing the Input Prime, Ground Truth Continuation and the Generated Continuation on a log scale. The y-axis is normalized to the tonic frequency of the input prime, i.e. 0 corresponds to the tonic frequency.
2. Sample with a slow movement in a low voice
Input Prime
Input Prime + Ground Truth Continuation (solid blue + dotted blue contour)
Input Prime + Generated Continuation (solid blue + orange contour)
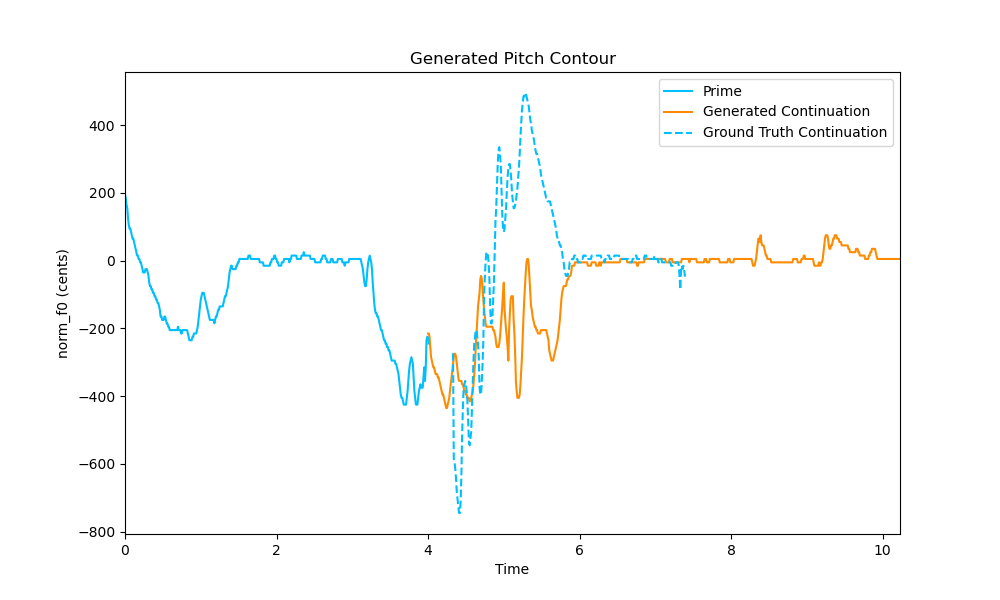
Pitch contour containing the Input Prime, Ground Truth Continuation and the Generated Continuation on a log scale. The y-axis is normalized to the tonic frequency of the input prime, i.e. 0 corresponds to the tonic frequency.